
Big-O#
Asymptotic analysis is a mathematical method used to describe the behavior of data structures and algorithms as the input size approaches infinity. It is a way of analyzing the computational cost of algorithms in terms of their efficiency and scalability.
In asymptotic analysis, we typically focus on the worst-case scenario of an algorithm, which is the scenario in which the algorithm takes the longest time to execute. We use big-O notation to express the upper bound of the computational cost in terms of the input size.
For example, if we have an algorithm that takes \(2n^2 + 3n + 1\) operations to complete a task, we can express its time complexity as \(O(n^2)\). This means that as the input size grows, the computational cost of the algorithm will grow no faster than the quadratic function of n.
Asymptotic analysis is important in data structures and algorithms because it helps us understand how efficient and scalable they are. By analyzing the time and space complexity of an algorithm, we can make informed decisions about which algorithms and data structures to use in different scenarios.
For example, if we have a large dataset, we may want to choose an algorithm with a lower time complexity even if it has a higher space complexity. Conversely, if we have limited memory resources, we may choose a data structure with lower space complexity even if it has a higher time complexity.
Overall, asymptotic analysis is a powerful tool for analyzing the efficiency and scalability of data structures and algorithms, and is essential for developing high-performance software systems.
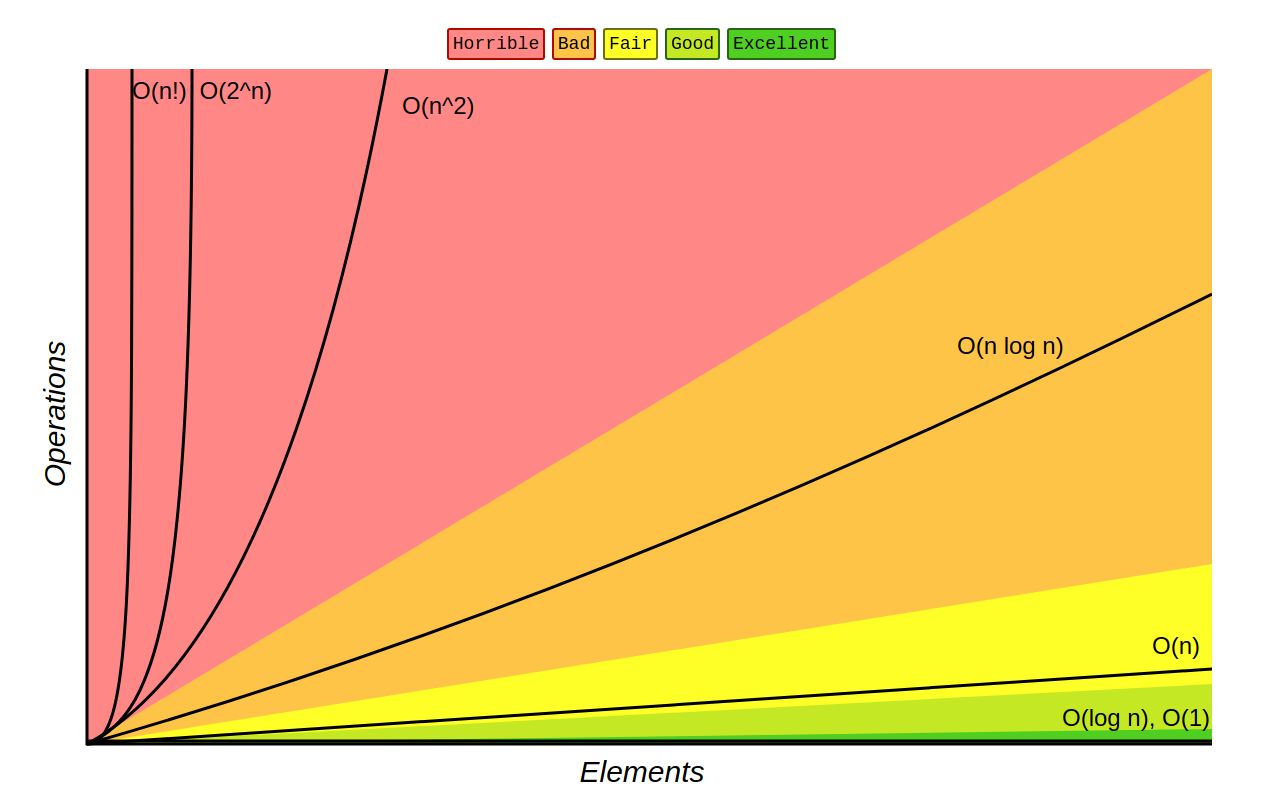
The story so far…#
Can measure actual runtime to compare algorithms
however, runtime is noisy (highly sensitive to hardware/software and implementation details)
Can count instructions to compare algorithms
can define \(T(n)\), which depends on the input size
for large inputs, our focus should be on the dominant terms of \(T(n)\)
Inline Math#
also known as a progression, is a successive arrangement of numbers in an order according to some specific rules
– gfg
Depending upon the number of terms in a sequence, it is classified into two types, namely a finite sequence and an infinite sequence.
examples
finite arithmetic sequence: \(3, 5, 7, 9, 11\)
infinite geometric sequence: \(2, 4, 8, 16, …… \)
Arithmetic Sequence and Series
where each term of the sequence is formed either by adding or subtracting a common term from the preceding number
\(2, 5, 8, 11, 14,…\)
common difference?
\(3\)
where each term of the sequence is formed either by multiplying or dividing a common term with the preceding number
\(1, 5, 25, 125, 625,…\)
common ratio?
\(5\)
where each term of the sequence is the reciprocal of the element of an arithmetic sequence
\(2, 5, 8, 11, 14,…\)
harmonic sequence?
\(1/2, 1/5, 1/8, 1/11, 1/14,…\)
Fibonacci Numbers
a sequence of numbers where each term of the sequence is formed by adding its preceding two numbers, and the first two terms of the sequence are 0 and 1
\(F_n\) ?
\(F_n = F_{n - 1} + F_{n - 2}\)

Fig. 93 sigma notation#
- general premise
\(\sum_{i = 1}^{n} 1 = n\)
sum of first n natural numbers
function sum_of_natural_numbers(n):
if n <= 0: return 0
else: return (n * (n + 1)) / 2
This pseudocode defines a function sum_of_natural_numbers that takes one parameter, \(n\), which represents the number of natural numbers you want to sum. It first checks if n is less than or equal to 0. If \(n\) is 0 or negative, it returns 0 because the sum of the first 0 natural numbers is 0. If \(n\) is greater than 0, it calculates the sum using the formula for the sum of an arithmetic series, which is \(\frac{(n * (n + 1))}{2}\). This formula efficiently computes the sum of the first n natural numbers in constant time.
sum of the squares
function sum_of_squares(n):
sum = 0
for i from 1 to n do:
sum = sum + (i * i)
return sum
This pseudocode defines a function sum_of_squares that takes one parameter, n, which represents the number of natural numbers whose squares you want to sum. It initializes a variable sum to 0 to keep track of the running sum of squares. It then uses a for loop to iterate from 1 to n (inclusive). Inside the loop, it calculates the square of the current value of i (i.e., i * i) and adds it to the sum. After the loop completes, it returns the final value of sum, which is the sum of the squares of the first n natural numbers.
sum of the cubes
function sum_of_cubes(n):
sum = 0
for i from 1 to n do:
sum = sum + (i * i * i)
return sum
This pseudocode defines a function sum_of_cubes that takes one parameter, n, which represents the number of natural numbers whose cubes you want to sum. It initializes a variable sum to 0 to keep track of the running sum of cubes. It then uses a for loop to iterate from 1 to n (inclusive). Inside the loop, it calculates the cube of the current value of i (i.e., i * i * i) and adds it to the sum. After the loop completes, it returns the final value of sum, which is the sum of the cubes of the first n natural numbers.
sum of the fourth powers of the first n natural numbers
function sum_of_powers_of_4(n):
sum = 0
power = 1
while power <= n do:
sum = sum + power
power = power * 4
return sum
This pseudocode defines a function sum_of_powers_of_4 that takes one parameter, n, which represents the limit up to which you want to calculate the sum of powers of 4. It initializes a variable sum to 0 to keep track of the running sum and power to 1, which represents 4^0 (the first power of 4). It uses a while loop to continue as long as power is less than or equal to n. Inside the loop, it adds the current value of power to the sum. It then updates the power by multiplying it by 4 to move to the next power of 4. The loop continues until power exceeds n, and then the function returns the final value of sum.
sum of the first n even natural numbers
function sum_of_even_natural_numbers(n):
if n <= 0: return 0
else: return n * (n + 1)
This pseudocode defines a function sum_of_even_natural_numbers that takes one parameter, n, which represents the number of even natural numbers you want to sum. It first checks if n is less than or equal to 0. If n is 0 or negative, it returns 0 because the sum of the first 0 even natural numbers is 0. If n is greater than 0, it calculates the sum using a formula. The sum of the first n even natural numbers is \(n * (n + 1)\), which is derived from the fact that even natural numbers are multiples of 2 (2, 4, 6, 8, …) and form an arithmetic sequence with a common difference of 2.
sum of the first n odd natural numbers
function sum_of_odd_natural_numbers(n):
if n <= 0: return 0
else: return n * n
This pseudocode defines a function sum_of_odd_natural_numbers that takes one parameter, n, which represents the number of odd natural numbers you want to sum. It first checks if n is less than or equal to 0. If n is 0 or negative, it returns 0 because the sum of the first 0 odd natural numbers is 0. If n is greater than 0, it calculates the sum using a formula. The sum of the first n odd natural numbers is \(n * n\), which is derived from the fact that odd natural numbers form a sequence of consecutive odd integers (1, 3, 5, 7, …) and can be represented as the square of n, where n represents the position in the sequence.
sum of the arithmetic sequence
for \(a, a + d, a + 2d, ... , a + (n - 1) d\)
function sum_of_arithmetic_sequence(first_term, common_difference, n):
if n <= 0: return 0
else: return (n * (2 * first_term + (n - 1) * common_difference)) / 2
This pseudocode defines a function sum_of_arithmetic_sequence that takes three parameters: first_term, common_difference, and n. first_term represents the first term of the arithmetic sequence. common_difference represents the common difference between consecutive terms of the sequence. n represents the number of terms you want to sum. It first checks if n is less than or equal to 0. If n is 0 or negative, it returns 0 because the sum of 0 terms in any sequence is 0. If n is greater than 0, it calculates the sum using the formula for the sum of an arithmetic sequence: \((n * (2 * first_term + (n - 1) * common_difference)) / 2\). This formula efficiently computes the sum of the first n terms of an arithmetic sequence.
geometric sequence
for \(a, ar, ar^2, ... , ar^{n - 1}\)
function sum_of_geometric_sequence(first_term, common_ratio, n):
if n <= 0:
return 0
else:
sum = 0
term = first_term
for i from 1 to n do:
sum = sum + term
term = term * common_ratio
return sum
sum of the first n terms $\( \begin {align} \Longrightarrow \sum_{i = 1}^{n} ar^{i - 1} = \frac{a(1 - r^n)}{1 - r} \\ \end {align} \)$
This pseudocode defines a function sum_of_geometric_sequence that takes three parameters: first_term, common_ratio, and n. first_term represents the first term of the geometric sequence. common_ratio represents the common ratio between consecutive terms of the sequence. n represents the number of terms you want to sum. It first checks if n is less than or equal to 0. If n is 0 or negative, it returns 0 because the sum of 0 terms in any sequence is 0. If n is greater than 0, it initializes a variable sum to 0 to keep track of the running sum and a variable term to first_term to represent the current term of the sequence. It then uses a for loop to iterate from 1 to n, adding the current term to the sum in each iteration. After adding the term to the sum, it updates the term by multiplying it by the common_ratio to get the next term in the sequence. The loop continues until n terms have been added to the sum, and then the function returns the final value of sum.
\(sum = \frac{first_term}{1 - common}\)
function sum_of_infinite_geometric_series(first_term, common_ratio):
if abs(common_ratio) >= 1:
# The series diverges if the common ratio is greater than or equal to 1.
return "Divergent (sum does not exist)"
else:
# Calculate the sum using the formula.
sum = first_term / (1 - common_ratio)
return sum
sum of the infinite terms $\( \begin {align} \Longrightarrow \sum_{i = 1}^{n} ar^{i - 1} = \frac{a}{1 - r}\), only when \(|r| \lt 1 \end {align} \)$
This pseudocode defines a function sum_of_infinite_geometric_series that takes two parameters: first_term and common_ratio. first_term represents the first term of the geometric series. common_ratio represents the common ratio between consecutive terms of the series. It first checks if the absolute value of common_ratio is greater than or equal to 1. If the common ratio is greater than or equal to 1, the series diverges, and the function returns “Divergent (sum does not exist)” because the sum does not exist in such cases. If the common ratio is less than 1, it calculates the sum using the formula mentioned earlier and returns the result.
Summation of the first N Integers : \(\sum_{i = 1}^n i\)
int main() {
int i, sum = 0, n;
scanf("%d", &n);
for(i=1; i<=n; i++) {
sum = sum + i;
}
printf("%d", sum);
return 0;
}
Comparing Algorithms#
Comparative rules
1.10.1 Comparison of Functions #1
1.10.2 Comparison of Functions #2
Explanation
Looking closely at the graphs, the left graph has low input (\(n\)) values…when we look to the right and reveal the graph for high input (\(n\)) values, the behavior of the lines on the graph remains the same. Therefore the algorithms themselves are the same…
Explantion
Looking closely at the graphs, the left graph has low input (\(n\)) values…when we look to the right and reveal the graph for high input (\(n\)) values, the behavior of the lines on the graph remains the same. Therefore the algorithms themselves are the same…
We are trying to compare \(T(n)\) functions, but…
we also care about large values of \(n\)
Can we properly define \(\le\) for functions?
we can group functions into \(sets\) and make our lives easier
Asymptotic Analysis#
refers to the study of an algorithm as the input size “gets big” or reaches a limit (in the calculus sense)
Growth rate#
rate at which the cost of an algorithm grows as the size of its input grows
Common sets of functions#
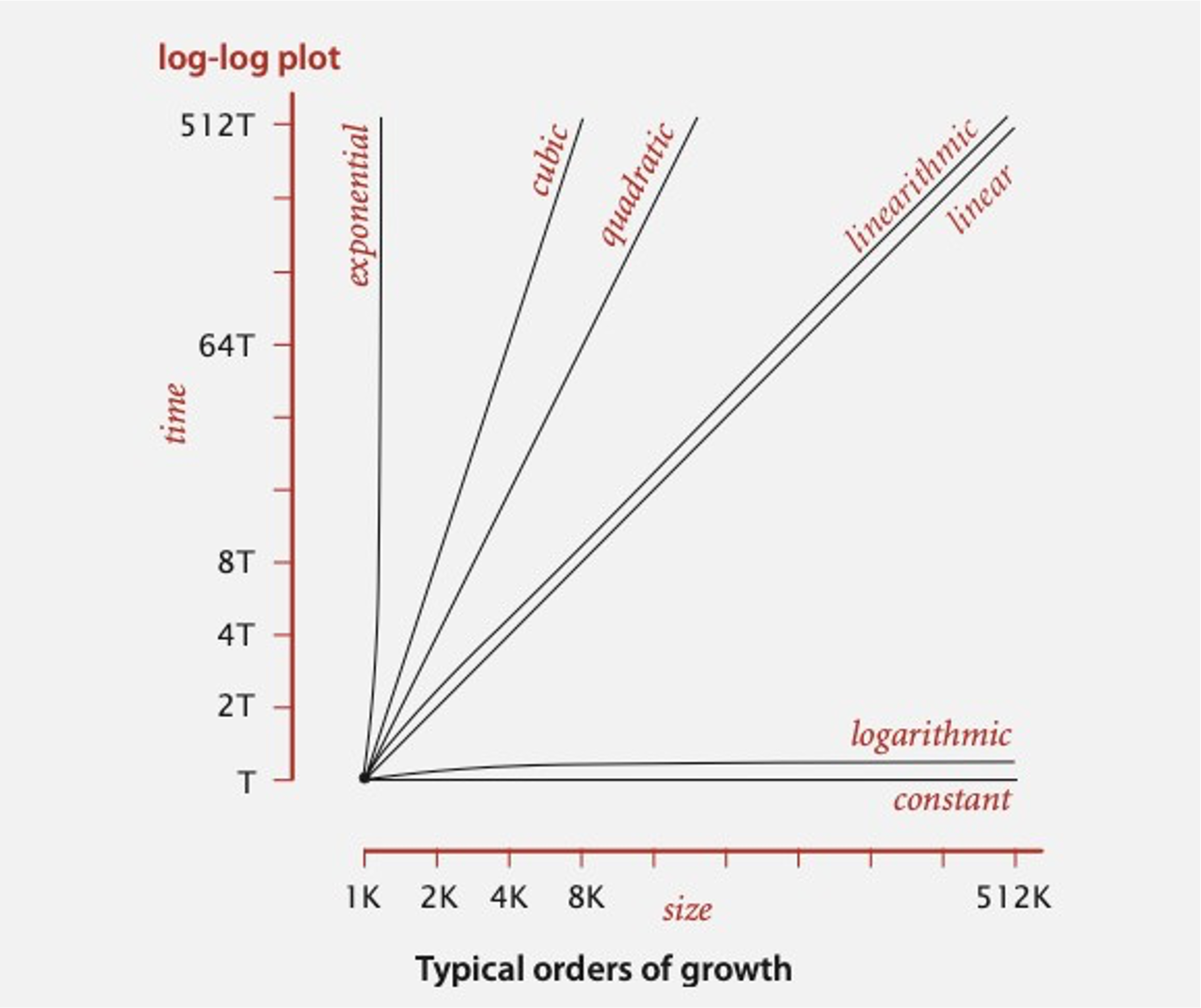
Algorithm \(A\) is better than Algorithm \(B\) if…
for large values of \(n\), \(TA(n)\) grows slower than \(TB(n)\)
Note: Faster growth rate…slower algorithm…
Examples#
order of growth |
name |
typical code framework |
description |
example |
|---|---|---|---|---|
\[1\]
|
constant |
\[a = b + c;\]
|
statement |
add two numbers |
\[log\ n\]
|
logarithmic |
\[\begin{split}while\ (n > 1)\\ \{ \ \ \ \ \ \ \ \dots \ \ \ \ \ \ \ \}\end{split}\]
|
divide in half |
binary search |
\[n\]
|
linear |
\[\begin{split}for\ (int\ i\ = 0; i \lt n; i++)\\ \{ \ \ \ \ \ \ \ \dots \ \ \ \ \ \ \ \}\end{split}\]
|
single loop |
find the maximum |
\[n\ log\ n\]
|
linearithmic |
\[see\ mergesort\]
|
divide & conquer |
mergesort |
\[n^2\]
|
quadratic |
\[\begin{split}for\ (int\ i\ = 0; i \lt n; i++)\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ for\ (int\ j\ = 0; j \lt n; j++)\ \ \ \ \ \ \ \ \ \\ \ \ \ \ \ \ \ \ \{ \ \ \ \ \ \ \ \dots \ \ \ \ \ \ \ \}\end{split}\]
|
double loop |
check all pairs |
\[n^3\]
|
cubic |
\[\begin{split}for\ (int\ i\ = 0; i \lt n; i++)\ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ for\ (int\ j\ = 0; j \lt n; j++)\ \ \ \ \ \ \ \ \ \\ \ \ \ \ for\ (int\ k\ = 0; k \lt n; k++)\\ \{ \ \ \ \ \ \ \ \dots \ \ \ \ \ \ \ \}\end{split}\]
|
double loop |
check all pairs |
\[2^n\]
|
exponential |
\[see\ combinatorial\ search\]
|
exhaustive search |
check all subsets |
Asymptotic Bounds#
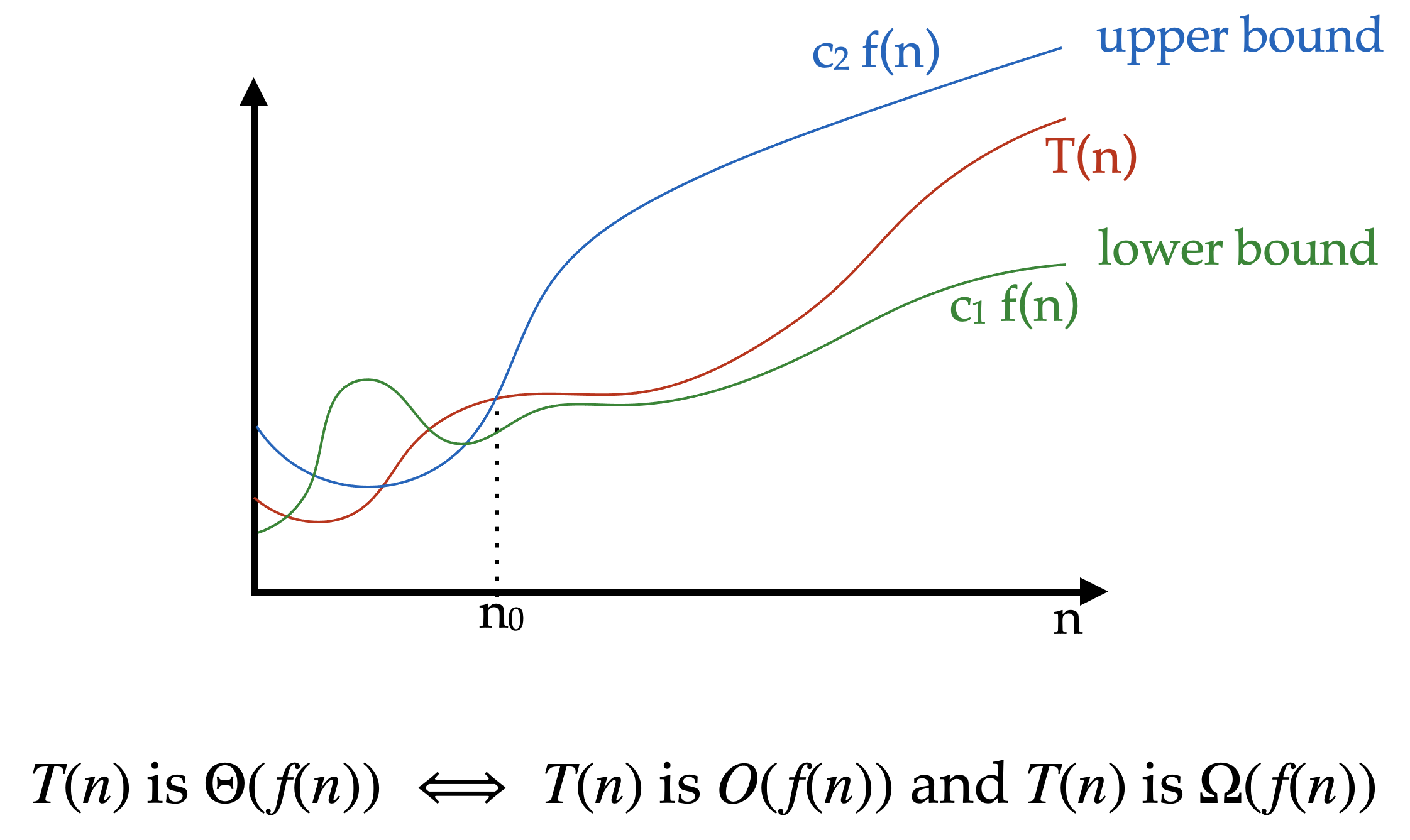
Asymptotic bounds are a way of describing the behavior of an algorithm as the input size approaches infinity. They are used to analyze the time and space complexity of algorithms, and are expressed in terms of upper and lower bounds.
The most commonly used asymptotic bounds are Big-O notation, Omega notation, and Theta notation.
Big-O notation is an upper bound on the growth rate of an algorithm. It describes the worst-case scenario of an algorithm’s time complexity.
Ex : if an algorithm has a time complexity of \(O(n^2)\), it means that the running time of the algorithm grows no faster than \(n^2\).
Big-Omega notation is a lower bound on the growth rate of an algorithm. It describes the best-case scenario of an algorithm’s time complexity.
Ex. if an algorithm has a time complexity of \(\Omega(n)\), it means that the running time of the algorithm grows at least as fast as \(n\).
Theta notation provides both an upper and lower bound on the growth rate of an algorithm. It describes the tight bound on the growth rate of an algorithm.
Ex. if an algorithm has a time complexity of \(\Theta(n^2)\), it means that the running time of the algorithm grows exactly as fast as \(n^2\).
Asymptotic bounds are useful because they allow us to compare the efficiency of different algorithms and to choose the most appropriate one for a given task.
Definition
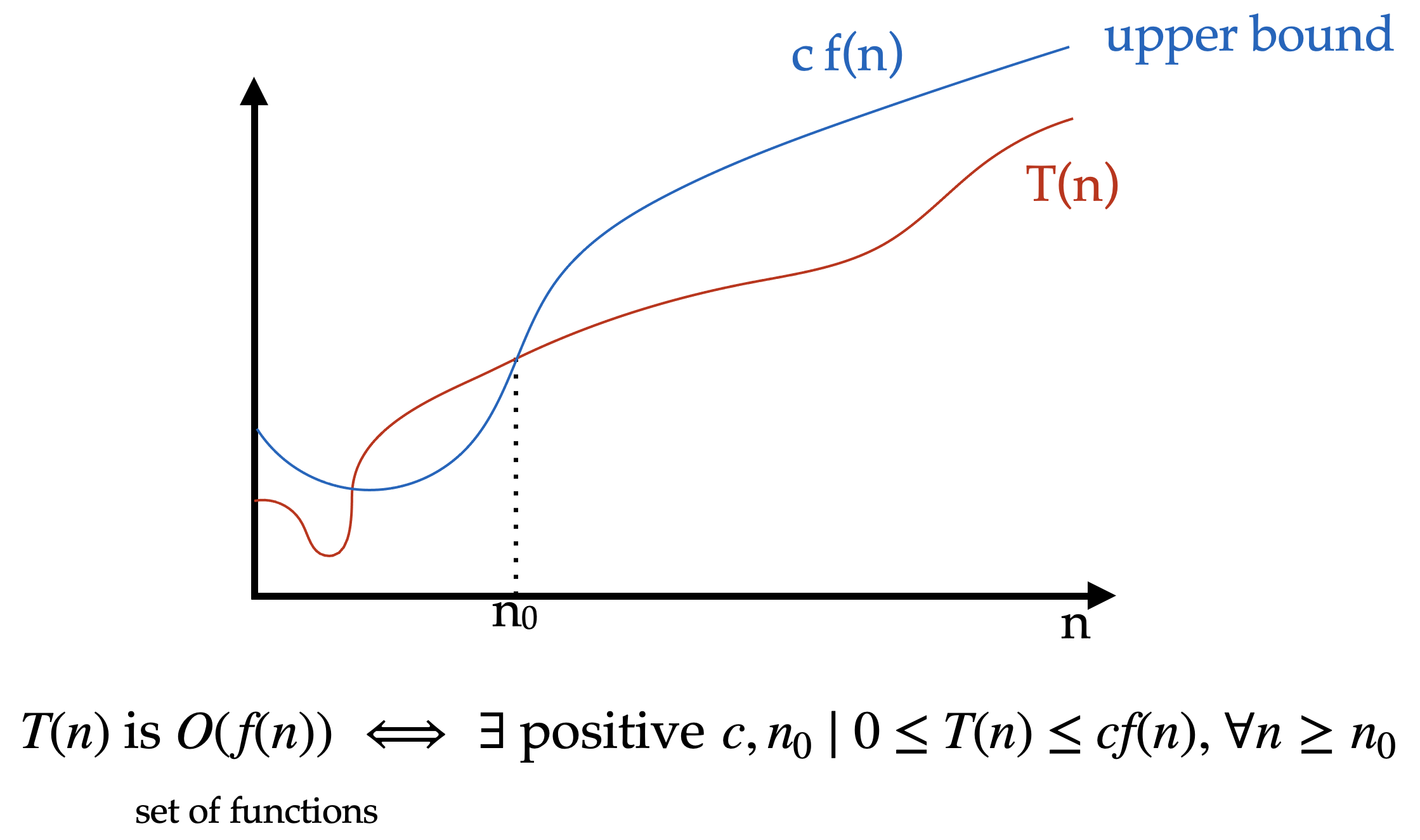
\(T\) of \(n\) is upper bounded by \(F\) of \(n\) if and only if \(T\) of \(n\) is less than or equal to some constant \(C\) times \(F\) of \(n\) the function we chose to bound with for all \(N\) greater than the initial \(n\) or and not
Definition
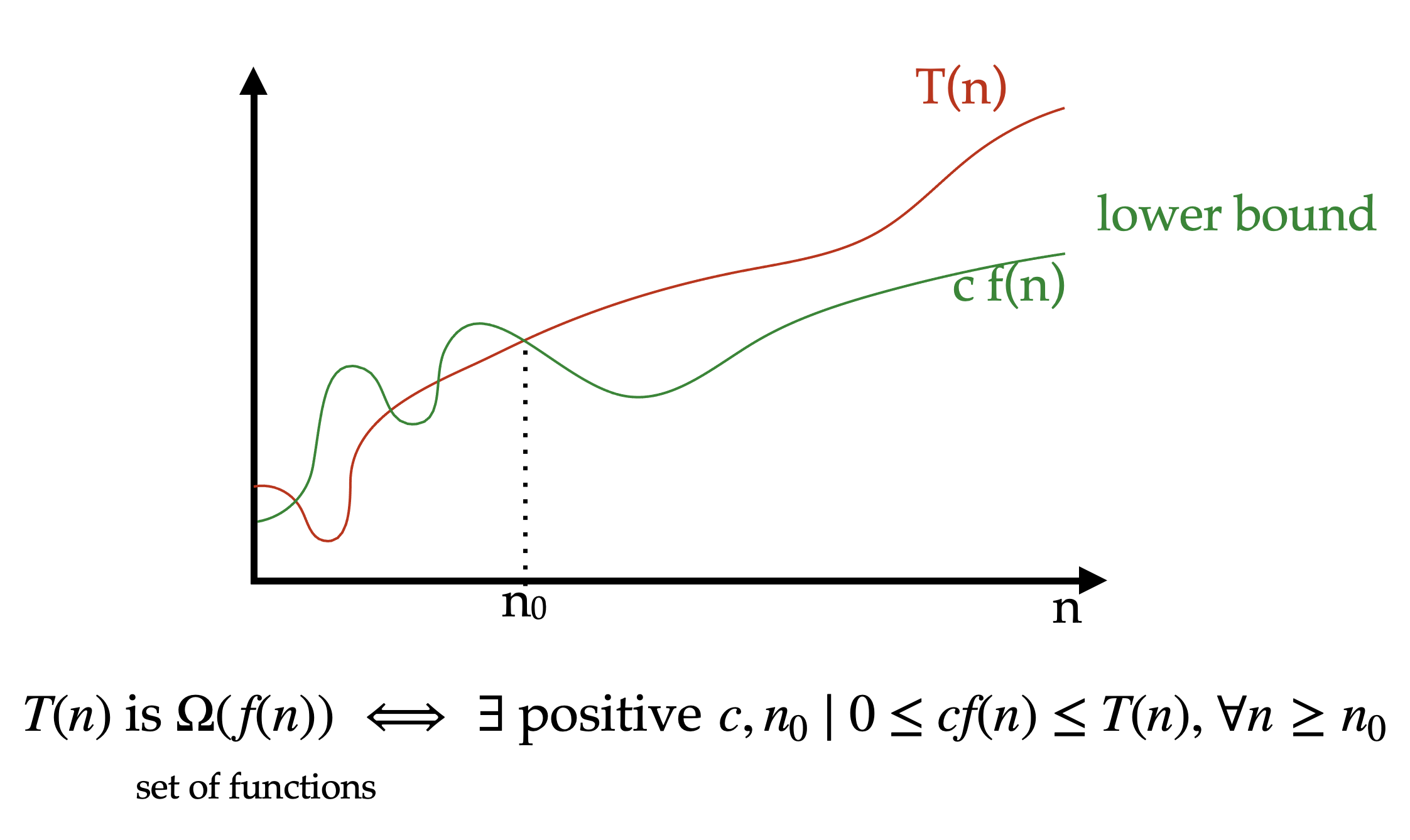
Definition
[1.8.2 Asymptotic Notations - Big Oh - Omega - Theta #2](https://youtu.be/Nd0XDY-jVHs?feature=shared)
In practice…#
“ignore constants and drop lower order terms”
Advantages & Disadvantages#
Advantages
Asymptotic analysis provides a high-level understanding of how an algorithm performs with respect to input size.
It is a useful tool for comparing the efficiency of different algorithms and selecting the best one for a specific problem.
It helps in predicting how an algorithm will perform on larger input sizes, which is essential for real-world applications.
Asymptotic analysis is relatively easy to perform and requires only basic mathematical skills.
– gfg
Disadvantages
Asymptotic analysis does not provide an accurate running time or space usage of an algorithm.
It assumes that the input size is the only factor that affects an algorithm’s performance, which is not always the case in practice.
Asymptotic analysis can sometimes be misleading, as two algorithms with the same asymptotic complexity may have different actual running times or space usage.
It is not always straightforward to determine the best asymptotic complexity for an algorithm, as there may be trade-offs between time and space complexity.
– gfg
True or False?#
Click near the center of a cell in each respective column to type your response…
\[Big\ O\]
|
\[Big\ \Omega\]
|
\[\Theta\]
|
|
|---|---|---|---|
\[10^2 + 3000n + 10\]
|
|||
\[21\ log\ n\]
|
|||
\[500\ log\ n + n^4\]
|
|||
\[\sqrt{n} + log\ n^{50}\]
|
|||
\[4^n + n^{5000}\]
|
|||
\[3000n^3 + n^{3.5}\]
|
|||
\[2^5 +n!\]
|
\[Big\ O\]
|
\[Big\ \Omega\]
|
\[\Theta\]
|
|
|---|---|---|---|
\[10^2 + 3000n + 10\]
|
\[\ge n\]
|
\[\le n\]
|
\[true\]
|
\[21\ log\ n\]
|
\[\ge log\ n\]
|
\[\le log\ n\]
|
\[true\]
|
\[500\ log\ n + n^4\]
|
\[\ge n^2\]
|
\[\le log\ n\]
|
\[false\]
|
\[\sqrt{n} + log\ n^{50}\]
|
\[\ge log\ n\]
|
\[\le log\ n\]
|
\[true\]
|
\[4^n + n^{5000}\]
|
\[\ge 2^n\]
|
\[\le n^2\]
|
\[false\]
|
\[3000n^3 + n^{3.5}\]
|
\[\ge n^2\]
|
\[\le n^2\]
|
\[true\]
|
\[2^5 +n!\]
|
\[\gt n!\]
|
\[\lt n!\]
|
\[false\]
|
Asymptotic Performance#
For \(large\) values of \(n\), a \(Θ(n^2)\) algorithm always beats a \(Θ(n^3)\) algorithm
However, we shouldn’t completely ignore asymptotically slower algorithms