
Sets#

Define#
A
setis a fundamental data structure in computer science that stores a collection of unique elements. It ensures that no duplicates are allowed, and it doesn’t impose a specific order on the elements.
An
unordered_setis a fundamental data structure in computer science that represents a collection of unique elements, similar to a mathematical set. It is implemented as a hash table, providing fast access and ensuring uniqueness of its elements. Unlike astd::set, it does not maintain any specific order of the elements.
Use Cases#
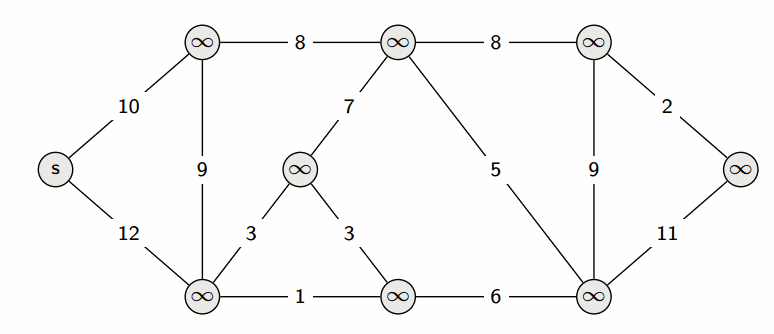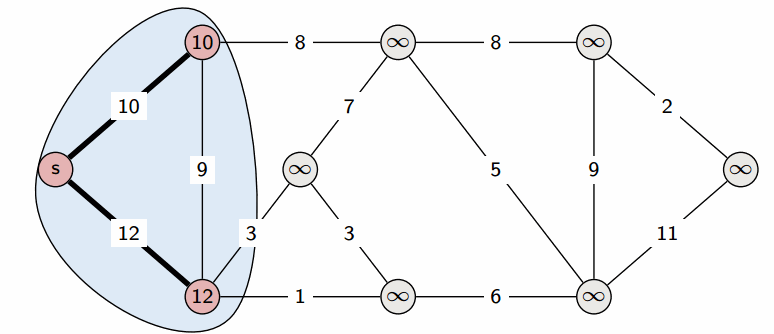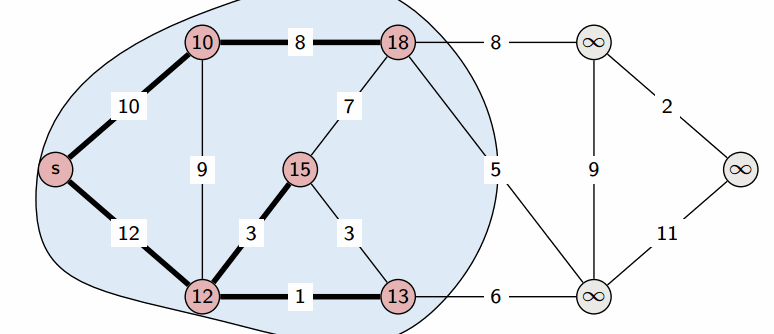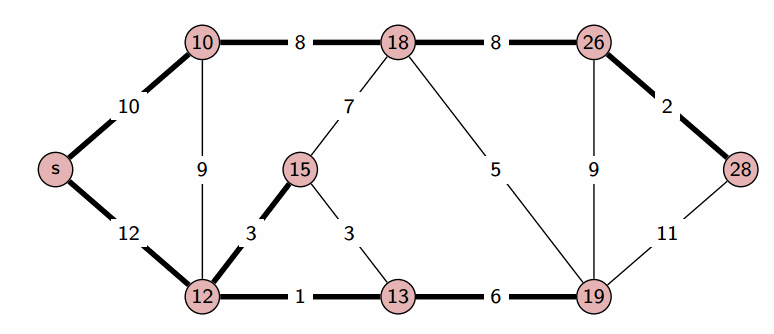
Sets can be used to track visited nodes in graph traversal algorithms.
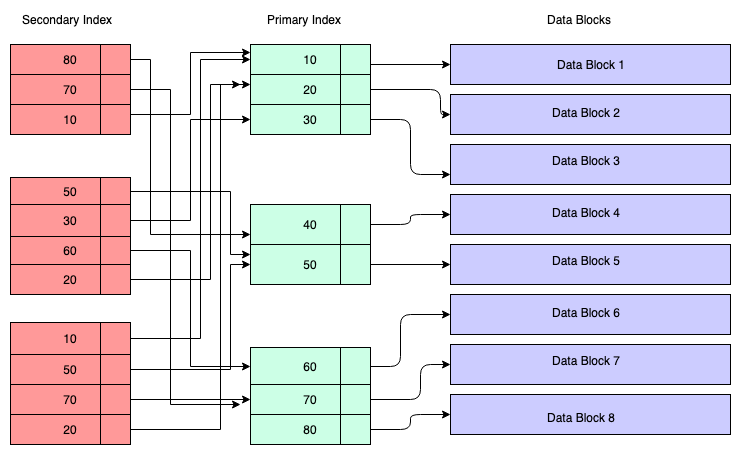
Sets are used to maintain unique values in database indexes, ensuring fast lookups.
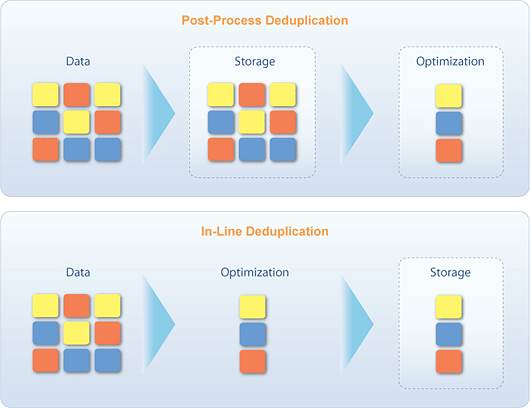
Removing duplicates from a list of records, such as emails or customer IDs.

Sets are efficient for checking whether an element is part of a specific group or category.
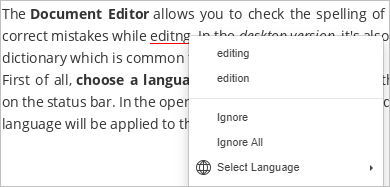
In word processing applications, a set can be used to maintain a dictionary of correctly spelled words.
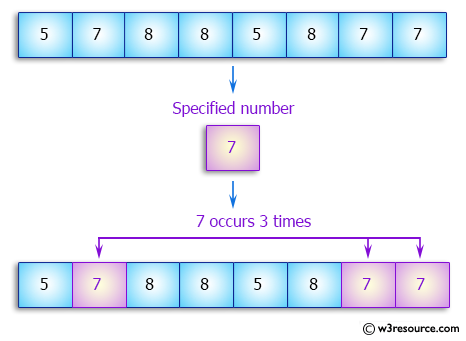
Counting the frequency of unique elements in a dataset.
Advantages & Disadvantages#
Uniqueness {both}
Sets enforce uniqueness, ensuring no duplicate elements.
Fast Lookup {both}
Efficient for searching and checking if an element exists.
Simple Interface {set}
Typically provides simple and intuitive methods like insert, contains, and remove.
Flexible Data Storage {unordered_set}
Suitable for scenarios where element order is not important.
No Ordering {both}
Elements are not stored in a specific order, which may be a disadvantage in some use cases.
Overhead {set}
May require more memory and have some overhead for maintaining uniqueness.
Slower Insertions {set}
Inserting elements can be slower compared to data structures optimized for insertion.
Hash Collisions {unordered_set}
In rare cases, hash collisions can lead to performance degradation.
Programming#
Set Data Structure:
- Initialize an empty set
- Implement functions for insert, delete, search, and traverse
We use the
std::unordered_setcontainer from the C++ Standard Library, which is a hash table-based implementation of a set.
We insert, check for existence, and remove elements using theinsert,find, anderasemethods.
Finally, we display the elements in the set.
1#include <iostream>
2#include <set>
3
4int main() {
5 std::set<int> mySet;
6
7 // Insert elements
8 mySet.insert(10);
9 mySet.insert(5);
10 mySet.insert(20);
11
12 // Search for an element
13 auto it = mySet.find(5);
14 if (it != mySet.end()) {
15 std::cout << "Element 5 found in the set.\n";
16 }
17
18 // Delete an element
19 mySet.erase(10);
20
21 // Traverse the set
22 for (const int& element : mySet) {
23 std::cout << element << " ";
24 }
25 std::cout << "\n";
26
27 return 0;
28}
Element 5 found in the set.
Set elements: 5 20
Unordered Set Data Structure:
Data:
- Initialize an array (buckets) of a fixed size for storing elements.
- Each bucket is a linked list to handle collisions.
Functions:
- Insert(value):
1. Calculate the hash of the value.
2. Find the bucket using the hash.
3. Search the bucket for the value; if not found, append the value to the bucket.
- Contains(value):
1. Calculate the hash of the value.
2. Find the bucket using the hash.
3. Search the bucket for the value; return true if found, false otherwise.
- Remove(value):
1. Calculate the hash of the value.
2. Find the bucket using the hash.
3. Search the bucket for the value, and if found, remove it.
- Display():
1. Iterate through each bucket and display the elements.
We use the
std::unordered_setcontainer from the C++ Standard Library, which is a hash table-based implementation of a set.
We insert, check for existence, and remove elements using theinsert,find, anderasemethods.
Finally, we display the elements in the set.
1#include <iostream>
2#include <unordered_set>
3
4int main() {
5 std::unordered_set<int> mySet;
6
7 // Insert elements
8 mySet.insert(10);
9 mySet.insert(5);
10 mySet.insert(20);
11
12 // Check if an element exists
13 if (mySet.find(5) != mySet.end()) {
14 std::cout << "Element 5 found in the unordered set.\n";
15 }
16
17 // Remove an element
18 mySet.erase(10);
19
20 // Display the elements
21 std::cout << "Unordered set elements: ";
22 for (const int& element : mySet) {
23 std::cout << element << " ";
24 }
25 std::cout << "\n";
26
27 return 0;
28}
Element 5 found in the unordered set.
Unordered set elements: 5 20
Compare#
|
|
|
|---|---|---|
Data Structure |
Balanced Binary Search Tree |
Hash Table |
Order of Elements |
Sorted, elements in ascending order |
No specific order |
|
\(O(log\ n)\) |
\(O(1)\) average, \(O(n)\) worst-case |
|
\(O(log\ n)\) |
\(O(1)\) average, \(O(n)\) worst-case |
|
\(O(log\ n)\) |
\(O(1)\) average, \(O(n)\) worst-case |
Element Order |
Preserved |
No specific order |
Memory Usage |
Relatively lower |
Relatively higher due to hash table |
Custom Key Types |
Requires operator< for keys |
Requires a hash function |
Range Iteration |
Efficient |
Less efficient |
Use Cases |
When elements need to be sorted |
When fast access times are critical, order doesn’t matter |
Extra Notes |
Well-suited for maintaining sorted collections. |
Suitable for fast access with no order requirement. |
Note: assume a well-designed/distributed hash function and minimal collisions. In practice, worst-case scenarios should also be considered, leading to amortized \(O(1)\) performance for many operations