
Maps#

Define#
A
mapis a data structure that associates unique keys with values. It enables efficient storage and retrieval of data, where each key is mapped to a corresponding value.
An
unordered_mapis a data structure in C++ that is part of the Standard Template Library (STL). It is an associative container that provides an unordered collection of key-value pairs. The keys in anunordered_mapare unique, and it allows for efficient storage and retrieval of data, similar to a dictionary. Unlike a map, it does not store elements in a specific order, making it more efficient for some operations.
Use Cases#
map#
Maps are used in database indexing to swiftly retrieve records based on unique keys, such as primary keys.
Compilers and interpreters employ maps to store identifiers (e.g., variable names) and associated attributes (e.g., data types).

Maps are used in caching mechanisms to quickly access cached data. Keys typically represent URLs, file paths, or query results.
In networking, maps are utilized to map destination addresses to routes for efficient packet forwarding.
unordered_map#
unordered_map can be used in caching mechanisms where keys represent queries or frequently accessed data, and values are the cached results.

It is helpful in counting the frequency of elements in a dataset, for example, counting word occurrences in a text corpus.
Storing configuration parameters in an unordered_map is common, where keys represent setting names and values store corresponding values.
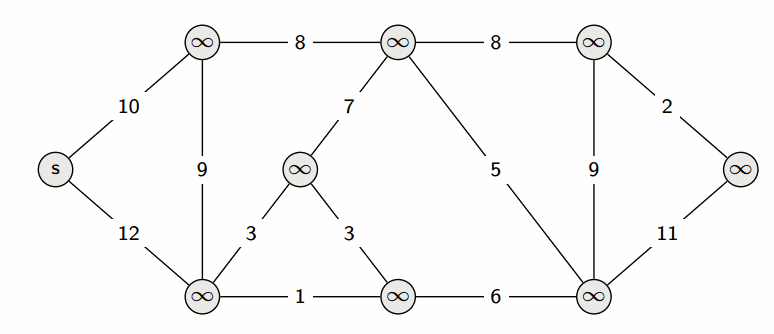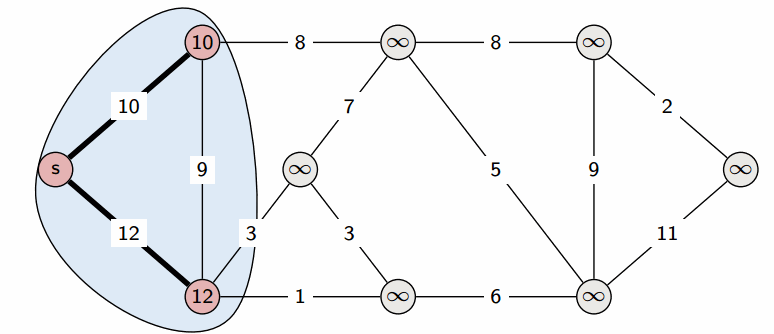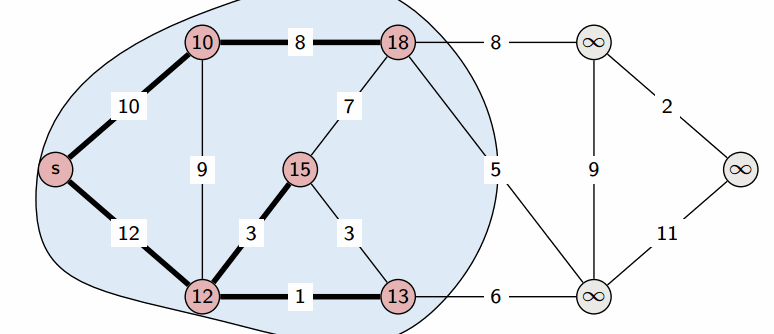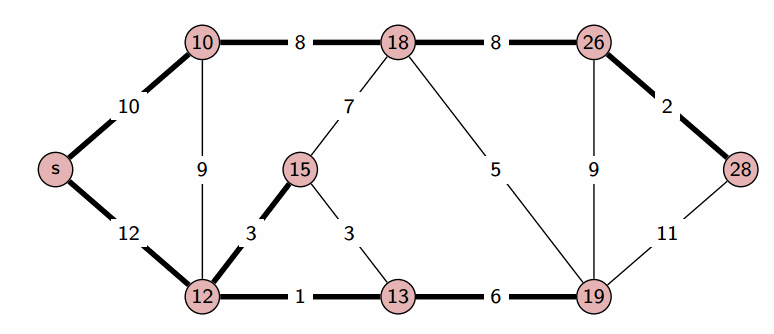
In graph algorithms like Dijkstra’s algorithm, an unordered_map can be used to track the shortest distance to each vertex.
Advantages & Disadvantages#
Efficient Retrieval {both}
Maps provide fast access to values based on their keys.
Customization {both}
You have control over the data structure, allowing for customization.
Versatility {map}
They can store various data types as values.
Enforces Uniqueness {map}
Maps ensure that keys are unique.
Hash-based {unordered_map}
It is implemented as a hash table, making it highly efficient for most operations.
Dynamic Sizing {unordered_map}
It automatically resizes when needed, which can be more memory-efficient.
Memory Overhead {both}
Hash tables used to implement maps may consume more memory due to internal data structures.
Hash Collisions {map}
Handling multiple keys mapping to the same index can lead to performance issues.
Not Ideal for Range Queries {map}
Maps are not designed for range-based searches, which could be inefficient.
Complexity for Custom Objects {unordered_map}
Defining a hash function for custom objects can be complex.
Unordered {unordered_map}
As the name implies, it does not maintain any specific order of elements.
Programming#
1. Create a Map class.
2. Initialize an array for storing key-value pairs.
3. Define a hash function to map keys to array indices.
4. Implement functions for key-value operations:
- Insert(key, value): Calculate the hash, store the (key, value) pair.
- Get(key): Calculate the hash, return the corresponding value.
- Remove(key): Calculate the hash, remove the (key, value) pair.
Define a
Mapclass with an array to store key-value pairs.
TheHashfunction calculates the index in the array for a given key using a simple hashing algorithm.
Insertadds a key-value pair to the map,Getretrieves a value by key, andRemovedeletes a key-value pair.
The main function demonstrates usage.
1#include <iostream>
2#include <vector>
3
4const int arraySize = 100; // Choose an appropriate size
5
6class Map {
7public:
8 Map() {
9 mapArray.resize(arraySize);
10 }
11
12 void Insert(std::string key, int value) {
13 int index = Hash(key);
14 mapArray[index] = std::make_pair(key, value);
15 }
16
17 int Get(std::string key) {
18 int index = Hash(key);
19 return mapArray[index].second;
20 }
21
22 void Remove(std::string key) {
23 int index = Hash(key);
24 mapArray[index] = std::make_pair("", 0);
25 }
26
27private:
28 std::vector<std::pair<std::string, int>> mapArray;
29
30 int Hash(std::string key) {
31 int hash = 0;
32 for (char c : key) {
33 hash = (hash * 31 + c) % arraySize;
34 }
35 return hash;
36 }
37};
38
39int main() {
40 Map map;
41 map.Insert("apple", 5);
42 map.Insert("banana", 3);
43
44 std::cout << "Value of 'apple': " << map.Get("apple") << std::endl;
45 map.Remove("banana");
46
47 return 0;
48}
Value of `apple`: 5
Note: Creating a pseudocode for unordered_map can be challenging due to the internal complexity of a hash table. However, here’s a simplified version
1. Create an UnorderedMap class.
2. Initialize a hash table with empty buckets.
3. Implement a hash function to map keys to buckets.
4. Implement functions for key-value operations:
- Insert(key, value): Calculate the hash, store the (key, value) pair in the corresponding bucket.
- Get(key): Calculate the hash, retrieve the value from the corresponding bucket.
- Remove(key): Calculate the hash, remove the (key, value) pair from the corresponding bucket.
Include the
unordered_mapheader to use theunordered_mapdata structure.
Create anunordered_mapcalled frequency_map with keys as strings and values as integers. Insert key-value pairs, access values by keys, and remove a key-value pair.
1#include <iostream>
2#include <unordered_map>
3#include <string>
4
5int main() {
6 std::unordered_map<std::string, int> frequency_map;
7
8 // Insert key-value pairs
9 frequency_map["apple"] = 3;
10 frequency_map["banana"] = 2;
11
12 // Access values by key
13 std::cout << "Frequency of 'apple': " << frequency_map["apple"] << std::endl;
14
15 // Remove a key-value pair
16 frequency_map.erase("banana");
17
18 return 0;
19}
Compare#
|
|
|
|---|---|---|
Data Structure |
Red-Black Tree |
Hash Table |
Order of Elements |
Sorted (based on keys) |
Unordered (no specific order) |
|
\(O(log\ n)\) |
\(O(1)\) average, \(O(n)\) worst-case |
|
\(O(log\ n)\) |
\(O(1)\) average, \(O(n)\) worst-case |
|
\(O(log\ n)\) |
\(O(1)\) average, \(O(n)\) worst-case |
Memory Usage |
Higher memory consumption |
Lower memory consumption |
Custom Key Types |
Requires operator< for keys |
Requires a hash function |
Range Iteration |
Efficient |
Less efficient |
Use Cases |
When elements need to be sorted or ordered |
When fast access times are critical, order doesn’t matter |
Note: assume a well-designed/distributed hash function and minimal collisions. In practice, worst-case scenarios should also be considered, leading to amortized \(O(1)\) performance for many operations